
Traditional interactive voice response (IVR) systems cause nearly 40% of customers to hang up before their issue is resolved. The system says “press 3 for billing.” The caller says “I just want to know why my invoice changed.” The call ends in frustration, the company logs a missed contact, and the cycle repeats tomorrow at scale.
AI voice agents are closing that gap in 2026 — not with a shinier menu, but with a fundamentally different approach to what a phone conversation can be.
Key takeaways
- AI voice agents combine automatic speech recognition, natural language understanding, and neural text-to-speech into a real-time pipeline that carries human-sounding conversations without a human on the other end of the line.
- The global AI voice agents market is projected to grow from USD 2.54 billion in 2025 to USD 35.24 billion by 2033, with customer support automation driving 44.2% of that growth.
- AI-generated voices have reached a level of realism where voice cloning accuracy exceeds 90%, making AI voice calls indistinguishable from human agents in most standard interactions.
- Organisations deploying conversational AI systems in their contact centres report 30 to 50% reductions in cost per call within 3 months.
- Building a voice agent involves 5 interconnected technical layers. Getting the handoffs between them right determines whether the agent feels fluid or frustrating.
- This article maps the full architecture so you can evaluate platforms, set honest expectations with stakeholders, and make better build decisions.
What AI voice agents actually are
AI voice agents are software-powered AI systems that listen to spoken language, understand intent in real time, reason about the best response, and reply in natural-sounding speech, all without a human involved in the conversation. They sit at the intersection of conversational AI systems, large language models (LLMs), and neural audio synthesis.
The term covers a wide range of deployments: an outbound AI voice call reminding a patient about an appointment, an inbound customer service AI handling return requests at a retail brand, or a conversational AI voice assistant helping a field engineer query inventory while their hands are occupied. What they share is the same core architecture, even when the use case looks different on the surface.
In 2026, AI voice agents have moved from proof-of-concept to production infrastructure. The market sits at USD 2.54 billion and is growing at a compound annual growth rate of 39%. That is not a forecast for a technology that is still finding its footing — it is adoption at scale, driven by a business case that closes quickly.
How AI voice agents work: the 5-layer pipeline
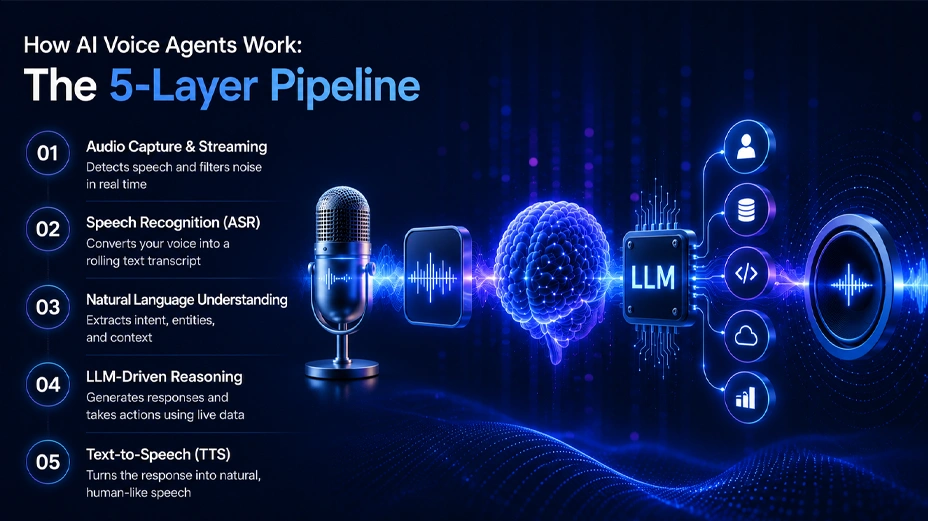
An AI voice agent works by moving spoken input through 5 sequential layers: audio capture and streaming, automatic speech recognition (ASR), natural language understanding (NLU), LLM-driven reasoning, and text-to-speech (TTS) synthesis. Each layer converts one format of information into another, and the speed of the handoffs between them determines whether the conversation feels natural or artificial.
Audio capture and streaming
The agent receives your voice as a raw audio stream. Modern production AI systems start processing before you have finished speaking, using voice activity detection (VAD) to identify active speech and filter out background noise. This layer sounds straightforward but it is frequently where production voice AI technology runs into trouble. Variable microphone quality, cross-talk, and environmental noise all affect what reaches the next layer, and problems here compound through every stage that follows.
Automatic speech recognition
ASR, also called speech-to-text (STT), converts the audio stream into a text transcript. In 2026, leading ASR providers such as Deepgram, AssemblyAI, and OpenAI’s Whisper handle multiple accents, fast speech, and domain-specific vocabulary with high accuracy. Streaming ASR is critical for conversational AI voice interactions: rather than waiting for a complete sentence, the system produces a rolling transcript so the reasoning layer can begin processing before the speaker finishes talking. This single design choice is the most direct lever for reducing the latency a caller perceives.
Natural language understanding
NLU takes the transcript and extracts meaning: what the speaker intended, what entities (names, dates, account numbers) are relevant, and what context from earlier in the AI voice conversation applies. In older conversational AI systems, this was a separate, rules-based component with its own intent taxonomy. In 2026, NLU is increasingly handled by the same large language model that drives reasoning, which simplifies the pipeline and significantly improves the agent’s ability to handle ambiguous, unexpected, or multi-part inputs.
LLM-driven reasoning
The language model receives the interpreted intent, the conversation history, and any relevant context retrieved from connected AI systems — CRM data, knowledge bases, APIs — and generates the appropriate response. This is where AI voice agents diverge most sharply from traditional IVR: the agent can hold multi-turn conversations, recover from misunderstandings, and take real actions (create a ticket, update a record, initiate a transfer) based on what it understood. Escalation logic, tone instructions, compliance guardrails, and persona all live in this layer.
Text-to-speech synthesis
The generated text response is converted back to speech. Current TTS engines produce AI-generated voices that handle prosody, pacing, and emotional register with enough accuracy that callers frequently cannot tell they are speaking to an AI in a standard AI voice conversation. Voice cloning accuracy on leading platforms now exceeds 90%. The result is AI voice calls that feel like dialogue rather than a machine reading back a script.
What makes AI-generated voices sound human in 2026
AI-generated voices have changed more in the last 2 years than in the previous decade. The shift is not only about fidelity — it is about expressiveness. Early neural TTS systems produced clear but flat speech: correct stress patterns, limited emotional range. Current models generate AI-generated voice output with variable pacing, emotional tags (hesitation, warmth, certainty), and accent control that earlier voice AI technology could not manage.
ElevenLabs’ Eleven v3, released in 2025, introduced support for unlimited speakers in a single generation, dynamic tonal shifts, and real-time cloning during live calls. OpenAI’s gpt-4o-mini-tts allows fine-tuning of pitch, speed, and tone, though independent evaluations find ElevenLabs leads on emotional depth. For enterprise deployments of customer service AI, the practical implication is straightforward: the quality of AI-generated voice is no longer the bottleneck. Reasoning quality and integration reliability are where most production failures originate.
Where AI voice agents are transforming customer service
The clearest commercial use case in 2026 is customer support AI. The numbers are specific enough to be useful in a business case.
A Forrester study on enterprise deployments found a 3-year ROI between 331% and 391%, with one composite organisation saving $10.3 million in agent labour costs over 3 years while halving call abandonment rates. McKinsey’sresearch on contact centres found a 50% reduction in cost per call alongside improved customer satisfaction scores. Traditional IVR containment rates sit at 20 to 40%; AI voice agents raise that to 50 to 75%, with first-call resolution climbing from roughly 65% to 85 to 95%.
Gartner predicts that by 2029, agentic AI will autonomously resolve 80% of common customer service issues without human intervention. A separate Gartner survey of 163 customer service leaders found that 95% plan to keep human agents and use AI to handle routine volume. That is the right framing. AI in customer support is not primarily a headcount replacement strategy in mature deployments — it is a triage and resolution layer that frees human agents for calls where empathy and judgement genuinely matter.
To make this concrete: a financial services client we worked with was handling 4,000 inbound calls per day, with 60% of those being routine queries: balance checks, transaction disputes, payment dates. After deploying a conversational AI agent on the inbound line, those routine calls were resolved in under 90 seconds without agent involvement. The human team shifted focus to complex escalations and outbound sales conversations. Resolution quality improved because agents were no longer distracted by volume — and AI in customer experience moved from a cost-saving argument to a service-quality one.
What it takes to build a voice agent in 2026

Building a voice agent means connecting 5 technology layers, managing sub-500ms latency across all of them, and integrating with your existing systems of record. A production-grade build takes 4 to 12 weeks depending on integration complexity, not conversational design.
Adopt streaming architecture from day one. A batch system that waits for a complete utterance before processing will feel unnatural even if the model is excellent. Streaming ASR, partial transcript processing, and speculative TTS generation are the difference between a 300ms round-trip and a 1,500ms one. Users accept the latter in a web form; they hang up on it during an AI voice call.
Separate orchestration from reasoning. The LLM should handle reasoning, not routing, error recovery, or escalation logic. Mixing them creates fragile AI systems that are difficult to debug and impossible to audit. Platforms like VAPI, Retell AI, and Bland AI handle orchestration as a managed layer, which reduces infrastructure complexity for teams focused on conversational design. When you build a voice agent on top of a well-managed orchestration layer, you spend your engineering time on the problems that actually differentiate the product.
Invest in integrations before going live. Conversational AI systems without live data are demos. The agent needs read and write access to your CRM, ticketing system, and knowledge base to resolve queries rather than just acknowledge them. Most of the build timeline on a real project goes into authentication, data mapping, and error handling on those integrations. Teams that underestimate this scope consistently miss their go-live target.
Build in evaluation from the start. Define what “resolved” means before you deploy, and instrument the agent to track it. Call-level metrics — containment rate, escalation rate, resolution time, customer satisfaction — give you the feedback loop needed to improve. Voice AI technology without measurement is a black box that grows harder to manage over time.
What 2026 is really telling us about voice AI
The organisations getting the most out of AI voice agents are not the ones with the most sophisticated conversational design. They are the ones that treated the agent as a systems integration problem from day one: fast audio streaming, live data connections, measurable resolution criteria, and a human escalation path that works when it matters.
As language models improve and AI-generated voices continue to close the gap with human speech, the real differentiation in voice AI technology will come from the quality of integrations and the specificity of the reasoning layer. A conversational AI agent with live access to accurate data will outperform a more sophisticated model working from stale context, every time.
That is the same principle we built JAM on. JAM (Just a Moment) is our in-house AI voice agent, designed for real-world deployment conditions: low-latency streaming, live system integrations, and a reasoning layer tuned to resolve rather than just respond. If you are evaluating whether to build or buy, or trying to work out why a deployed AI voice agent is not hitting its resolution targets, we are happy to look at it with you. Write to us at coffee@sparkeighteen.com and tell us what you are working with.


