
For about 2 years, getting value from ai tools for coding followed the same pattern: write a prompt, review the output, catch the mistake, write another prompt. Developers got faster at this. They built internal libraries of reliable instructions, called it ai prompt engineering, and treated it as a core skill. Then in June 2026, a shift began to crystallise across engineering teams. Writing prompts was still valuable — but the real leverage had moved one layer up. Instead of prompting agents turn by turn, engineers started designing the systems that prompt agents automatically, observe the results, and retry without human involvement.
That discipline has a name: Loop Engineering.
Key takeaways
- Loop Engineering is the practice of designing systems that run iterative agent cycles: trigger, instruct, act, verify, and loop, without requiring a human to prompt each turn.
- Ai prompt engineering, context engineering, and loop engineering are sequential layers of the same idea. Each moved the leverage point further up the stack, from the instruction to the system that generates instructions.
- A production-grade loop has 5 components: a loop policy, a tool surface, context and memory management, a verification layer, and observability. Missing any one creates a system that works in demos and fails in production.
- A 2026 survey found that 82% of IT and data leaders now agree that prompt engineering alone is no longer sufficient for AI at scale. The teams outperforming are designing architectures, not crafting prompts.
- Ai tools for coding like GitHub Copilot, Cursor, and Claude Code are converging on loop-compatible primitives. Knowing how to design a loop determines how much value you extract from them.
- This article gives you a working map of the loop engineering stack, the failure points to design around, and what it looks like applied to a real build.
What loop engineering actually is
Loop Engineering is the practice of designing automated systems that drive large language model (LLM) agents through repeated action-observe-reason-retry cycles until a goal is met or a stopping condition is triggered, without a human in the prompt loop. You are no longer the person who writes each instruction. You are the person who designs the policy that generates instructions, the environment the agent acts in, and the gates that determine whether the output is acceptable.
The phrase crystallised in 2026, but the underlying idea had been building for 2 years. A 2026 survey confirmed that 82% of IT and data leaders now agree that ai prompt engineering alone is insufficient for production AI at scale. The organisations closing that gap are not writing better prompts. They are building better loops.
What makes a loop different from a chain? A chain runs steps in a fixed sequence: do A, then B, then C. A loop is dynamic. The agent takes an action, observes the result, reasons about whether it is correct, and decides whether to retry, branch, or escalate. That flexibility is what makes loops capable of handling tasks where the right path is not known upfront — which describes most real engineering work.
The evolution: from prompt engineering to loop engineering
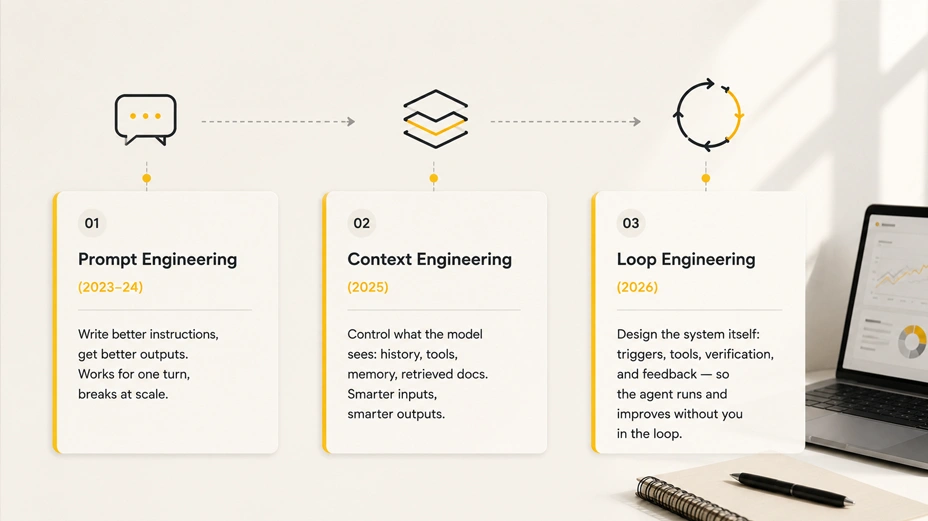
Understanding loop engineering requires tracing what came before it, because each layer solved a real limitation of the one before it.
Prompt engineering (roughly 2023 to 2024) was about instruction quality. If the model gave a poor output, the fix was a better prompt: more specific instructions, a clearer format requirement, a worked example. Ai prompt engineering tools like OpenAI’s prompt playground and structured prompt templates helped teams standardise this. The limitation was that a well-crafted prompt solves one turn. In a multi-step workflow, you need to re-prompt at every step, and that does not scale when the workflow runs dozens of iterations.
Context engineering (2025) recognised that the prompt was never the whole problem. What the model sees during inference — its context window — includes system instructions, tool definitions, conversation history, retrieved documents, and memory. Context engineering is the discipline of managing that entire information surface: deciding what to include, what to compress, what to retrieve, and what to discard. Anthropic’s engineering team published on this in 2025, positioning prompt and context engineering as a natural progression. The limitation of context engineering alone is that it still assumed a human was deciding when to pass context and when to trigger the next action.
Loop Engineering (2026) moves the human one level further up. You are no longer managing prompts or context turn by turn. You are designing a system: a policy that triggers agent runs, a harness that equips the agent with tools and constraints, a verification layer that evaluates outputs, and a feedback mechanism that feeds corrections back into the next cycle. The human’s job becomes designing and improving the loop, not running it.
This is not a marginal upgrade in how you use ai engineering tools. Research shows that structured prompt processes reduce AI errors by up to 76%. When you move from ad hoc prompting to a designed loop, you institutionalise that structure for every agent run — not just the ones you personally oversee.
The 5 building blocks of a well-designed agent loop
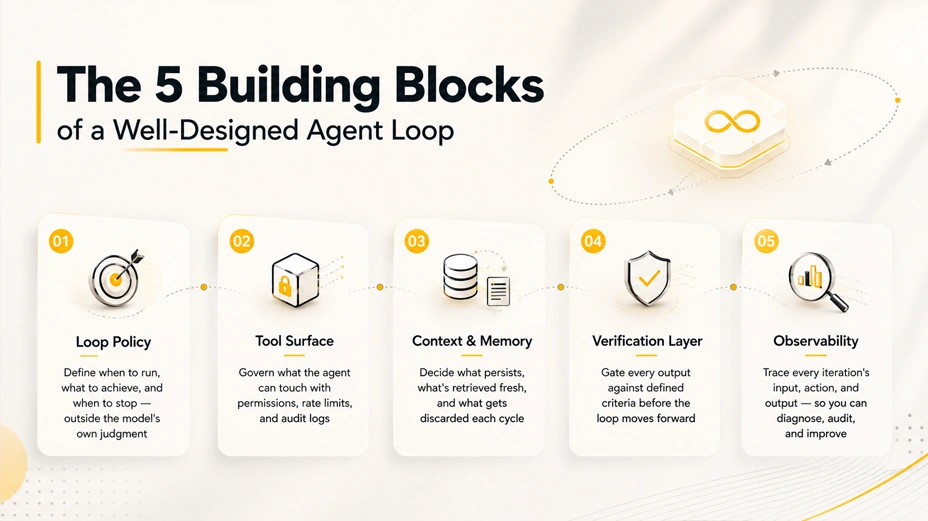
A production-ready loop has 5 components. Most teams build 3 of them well and treat the other 2 as optional. That is usually where the failure happens.
1. Loop policy
The loop policy is the logic that decides when to run the agent, what goal to give it, and when to stop. This sounds straightforward but it is the most overlooked component in early builds. Teams that skip explicit policy design end up with agents that run indefinitely on an ambiguous goal, or stop too early because the stopping condition relied on the model’s own judgment. A well-designed loop policy has 3 things: a trigger (time-based, event-driven, or in response to an external signal), a goal specification the agent can evaluate against, and a stopping condition that sits outside the model’s self-assessment. Engineering prompts without a clear loop policy is like writing good code for a system with no defined exit condition.
2. Tool surface
The agent needs tools to act: file access, code execution, application programming interface (API) calls, database writes, browser automation. The tool surface defines what the agent can and cannot touch. In loop engineering, the tool surface is not just a list of capabilities — it is a governed interface with permissions, rate limits, and audit logs. Giving an agent unlimited tool access in a loop is the agentic equivalent of giving a new developer root access on their first day. The best ai code assistant tools in 2026, including Claude Code and Cursor, both expose tool-definition primitives that let you control this surface precisely. How you define the tool surface is as important as the ai prompt engineering that drives the reasoning.
3. Context and memory management
Each iteration of the loop needs the right information in the model’s context window: what happened in the previous step, what the current codebase or system state looks like, what rules and constraints apply. Memory management determines whether the agent learns across iterations or restarts from scratch every cycle. A loop without memory is a loop that repeats the same mistakes. Effective prompt and context engineering at this layer means deciding what persists across iterations (task state, correction strings from failed attempts, architectural constraints), what gets retrieved fresh (relevant files, documentation), and what gets discarded (stale context that wastes tokens and degrades reasoning quality).
4. Verification layer
This is the component most teams skip and most loops fail without. Verification is a rule-based gate that checks the agent’s output against defined criteria before the loop proceeds, before anything is committed to production, and before the next iteration starts. Without it, a single hallucination cascades: the agent writes incorrect logic, the loop accepts it, the next iteration builds on top of it, and by iteration 5 the system is reasoning from a false premise. Verification does not need to be complex. Linting, test execution, schema validation, and structured output checks cover most cases. The key is that verification runs outside the agent’s own judgment, because asking the agent to evaluate its own output is not a reliable gate in any ai for engineering context.
5. Observability
A loop that runs without observability is a black box. You cannot improve what you cannot measure, and in a multi-iteration agentic system you need to know which step failed, what context the agent had at that point, what tool call it made, and what the verification gate returned. Observability means structured traces, not just logs: a record of each iteration’s input, reasoning, actions, and output, searchable and auditable after the fact. This is not optional for production systems. It is how you diagnose failures, prove compliance to stakeholders, and improve the loop based on evidence rather than intuition.
How ai tools for coding are converging on loop-compatible design
The ai programming tools that developers rely on in 2026 are all moving toward the same architectural direction, even when they frame it differently.
GitHub Copilot surpassed 20 million users in July 2025. Developers using it complete tasks 55% faster on average. But the teams using Copilot as a loop component — feeding outputs through automated tests, checking them against an architecture spec, and retrying on failure — report significantly higher reliability than those using it turn by turn. The tool is the same. The loop design is different.
Cursor and Claude Code both expose primitives designed for harness and loop integration: custom agents, context injection, rule files, and governed tool definitions. In a January 2026 JetBrains survey, they share second place in developer adoption, behind Copilot. Claude Code awareness rose from 31% to 57% across 3 survey waves in less than a year, which reflects how quickly engineering teams are moving toward ai tools for programming that fit into designed workflows rather than ad hoc interactions.
The right question when evaluating ai tools for coding in 2026 is not “which gives the best single-turn output?” It is: does this tool support streaming output that a verification layer can read in real time? Does it expose tool-use APIs a harness can govern? Can context be injected externally? Those criteria separate tools that work reliably in production loops from tools that work reliably in demos.
Where loops break: the failure modes to design around
The teams we worked alongside at Spark Eighteen on agentic builds consistently encountered the same failure patterns, and they are almost never about model quality.
The most common failure is an underspecified goal. The loop policy sends the agent a task like “improve the onboarding flow” without defining what improvement means, what success looks like, or what the scope is. The agent does something, the loop accepts it because there is no verification gate, and the team discovers 3 iterations later that the agent has restructured the entire module based on its own interpretation. Fixing this is not an ai prompt engineering problem. It is a system design problem.
The second failure is missing context at iteration boundaries. Each loop iteration starts fresh if memory management is not designed deliberately. An agent that caught a critical edge case in iteration 2 has no record of it in iteration 4, and reintroduces the problem. Prompt and context engineering at the iteration boundary is where most reliability gains come from once the basic architecture is in place.
The third is over-permissive tool access. In early builds, teams tend to give agents broad access to move quickly. In a loop context, a single reasoning error can propagate into a database write, a file deletion, or an API call that cannot be reversed. The tool surface needs to be as narrow as the task requires, with human-approval gates on consequential actions until the loop has proven itself reliable in your specific environment.
The prompt is no longer the product
For the first engineering teams to understand this shift, the advantage is compounding. A well-designed loop improves with every iteration: the verification layer catches errors, memory retains corrections, and observability surfaces patterns across runs. A developer who prompts turn by turn hits a ceiling at their own speed. A loop runs continuously, learns from its failures, and scales independently of the team’s availability.
The most reliable agentic systems being built in 2026 are not being built by the teams with the best ai prompt engineering instincts. They are being built by teams that stopped treating the prompt as the product and started treating the loop as the architecture. The prompt became one component in a governed, observable system — necessary, well-designed, but no longer sufficient on its own.
If you are designing an agentic system or trying to move a proof-of-concept loop into a production-grade build, write to us at [email protected]. We are happy to work through the architecture with you.


