There is a version of this conversation happening in engineering teams everywhere right now. A senior engineer is arguing for more testing time before a release. A product manager is pushing back on the timeline slip. A CTO is trying to referee, quietly aware that production has broken twice in the last quarter and confidence is low on all sides.
The real problem is rarely the code. It is the architecture of how decisions get made and how changes get validated before they reach users. When that architecture is opaque, when the only way to know if something works is to ship it and hope, teams slow down instinctively, not out of laziness but out of reasonable self-preservation.
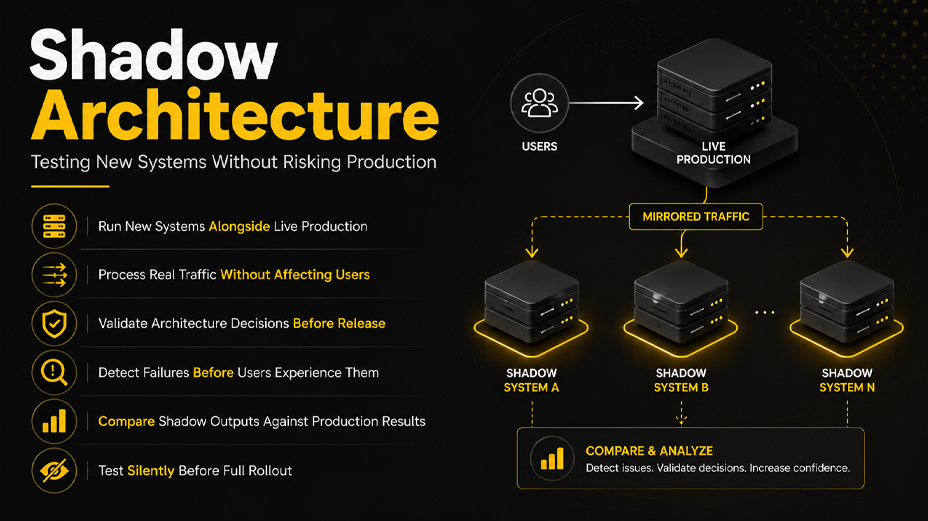
Shadow architecture is the method that breaks this deadlock. It does not ask teams to take on more risk. It restructures how risk is distributed across the release pipeline so that the vast majority of validation happens in parallel with production rather than before or after it.
The result, done well, is a genuine 3x improvement in software development speed, not by cutting corners, but by eliminating the structural bottlenecks that turn cautious teams into slow ones.
Key Takeaways
- Shadow architecture lets engineering teams validate new systems in parallel with production, dramatically reducing release risk without slowing delivery.
- Parallel canary universes extend the classic canary deployment model into a multi-track, isolated testing environment, giving teams real-world signals without real-world consequences.
- Architecture decision reversibility scoring is a practical framework for quantifying how “undoable” a technical decision is before you commit to it, protecting production stability without creating analysis paralysis.
- Teams that combine shadow architecture with structured reversibility scoring consistently ship faster because they eliminate the fear-driven slowdowns that kill deployment cadence.
- This is not a theoretical pattern. It is a set of concrete DevOps strategies used by high-performing engineering organisations at companies like Google, Netflix, and Stripe.
What Is Shadow Architecture?
Shadow architecture is a software delivery pattern in which a new or modified system component runs in parallel with the existing production system, receiving the same live traffic inputs but without its responses being returned to end users. The shadow system operates silently, processing real requests, generating real outputs, and logging real results, while production continues to handle actual user interactions unchanged.
The term draws on “shadow mode” testing, a concept well-established in systems engineering. What has evolved in modern DevOps strategies is the formalisation of shadow architecture as a structured, multi-layer approach rather than a one-off testing technique.
At its core, shadow architecture rests on three principles:
- Isolation — the shadow system cannot affect production behaviour, even if it fails catastrophically.
- Fidelity — the shadow system receives real production traffic, not synthetic or sampled data, so its behaviour reflects genuine usage patterns.
- Observability — the shadow system’s outputs are fully logged and compared against production, surfacing divergences before any user is exposed to them.
This combination is what makes shadow architecture fundamentally different from staging environments, blue-green deployments, or feature flags in isolation. Those tools help manage releases. Shadow architecture validates entire architectural decisions before committing to them.
Why Software Development Speed Stalls: The Real Bottleneck
Before getting into the mechanics, it is worth being precise about what actually slows teams down. It is rarely a lack of engineering effort or poor individual performance. The structural causes of slow software development speed are almost always one of the following:
1. Fear of production breakage: When teams have been burnt by incidents, deployment frequency drops. Engineers add more manual checks. Review cycles lengthen. Each of these responses is rational individually, but collectively they compound into a culture of slow shipping.
2. Irreversible architecture decisions: When a technical choice, a new database, a microservices split, or a third-party integration is expensive or painful to reverse, teams spend disproportionate time validating it upfront. This is rational risk management, but it kills momentum.
3. Inadequate pre-production signal: Staging environments notoriously fail to replicate production conditions. Load profiles, data shapes, and integration behaviours in staging diverge from production over time. Teams that rely heavily on staging are essentially making decisions with low-quality information.
4. Sequential validation gates: Traditional release pipelines validate changes sequentially: unit tests, integration tests, staging, UAT, and production. Each gate adds calendar time. Shadow architecture collapses several of these gates into a parallel track, compressing the validation timeline without removing the validation.
Research from the DORA (DevOps Research and Assessment) The State of DevOps Report consistently shows that elite engineering teams deploy 973x more frequently than low performers and have a 6,570x faster lead time from commit to production. (Source: Google Cloud DORA Report 2023) The gap is not talent, but it is the structural architecture of how changes flow through the system.
Parallel Canary Universes: Extending the Canary Model
Most engineers are familiar with canary deployments: releasing a change to a small percentage of production traffic first, observing behaviour, then progressively rolling out to the full user base. It is a well-established production stability technique that has become standard practice in mature engineering organisations.
Parallel canary universes take this a step further. Rather than a single canary track receiving a percentage of traffic, the model creates multiple isolated canary environments — “universes” — each running a distinct variant of the system simultaneously. Each universe receives real production traffic via mirroring or forking, operates in full isolation, and produces observable outputs that can be compared against each other and against production.
Why “Universes” Rather Than Simply Multiple Canaries?
The distinction matters for two reasons.
First, in standard canary deployments, the canary is in the release path — its responses do reach users. If it fails badly, some users are affected. In parallel canary universes, the universes are shadow environments. Their responses are logged but not served. This means you can run architecturally risky experiments with zero user exposure.
Second, multiple universes allow comparative testing across architectural variants in real time. You are not just asking “does this new version work?” — you are asking “which of these three approaches performs best under real production load?” That is a fundamentally richer signal for architecture decision making.
How Parallel Canary Universes Work in Practice
Here is the typical implementation pattern:
- Traffic mirroring — a proxy layer (often implemented via tools such as Envoy, NGINX mirroring, or a custom request forker) duplicates incoming production requests and sends copies to each canary universe.
- Response divergence logging — each universe’s response is compared against production and against other universes. Divergences are logged with full request context for analysis.
- Automated health scoring — each universe is assigned a health score based on error rates, latency percentiles, and response divergence. Universes falling below the threshold are automatically flagged.
- Promotion gates — once a universe’s health score crosses a defined threshold over a sufficient observation window, it is eligible for promotion to production via a standard canary or blue-green rollout.
This pattern is used at scale by organisations including Google, where a variant of this model is described in their Site Reliability Engineering literature (Google SRE Book, Chapter on Release Engineering), and by Netflix, whose engineering blog has documented shadow traffic techniques extensively as part of their resilience engineering practice.
The Key Benefits of Parallel Canary Universes
- Zero user exposure during validation — architectural experiments carry no production risk to end users.
- Real traffic fidelity — validation happens against actual usage patterns, eliminating the staging-production divergence problem.
- Comparative architectural signal — teams can evaluate multiple implementation options simultaneously rather than sequentially, compressing architecture decision making timelines significantly.
- Faster rollback confidence — because production has been running continuously and untouched, rollback is instantaneous if a promoted change later shows issues.
Architecture Decision Reversibility Scoring
This is the part that most shadow architecture discussions skip over, and it is arguably the more valuable half of the method.
Not all architectural decisions carry the same risk profile. Choosing a caching strategy is a very different commitment from choosing a primary database engine. The problem is that engineering teams often treat all architectural decisions with a similar level of caution which means they over-invest in validating low-risk choices and under-invest in scrutinising the ones that actually matter.
Architecture decision reversibility scoring is a lightweight framework for quantifying how difficult a technical decision would be to reverse and calibrating the validation investment accordingly.
The Reversibility Scoring Model
Each architectural decision under consideration is scored across four dimensions:
1. Reversal Cost (RC) — scored 1 to 5 How expensive, in engineering effort and calendar time, would it be to undo this decision if it proves wrong?
- 1 = Trivially reversible (e.g., a feature flag toggle)
- 5 = Extremely costly to reverse (e.g., migrating to a new primary database with a year of accumulated data)
2. Production Blast Radius (PBR) — scored 1 to 5 If this decision causes a production incident, how many users or systems are affected, and how severely?
- 1 = Localised impact, easily isolated
- 5 = Full system outage or widespread data integrity issue
3. Dependency Lock-in (DL) — scored 1 to 5 Does this decision create downstream dependencies that would be painful to unravel?
- 1 = No meaningful downstream dependencies created
- 5 = Extensive third-party or cross-team dependencies created that would require significant coordination to unwind
4. Observability Lead Time (OLT) — scored 1 to 5 How quickly will you know if this decision was wrong?
- 1 = Instant feedback (error rates spike within minutes)
- 5 = Slow feedback (problems may take weeks or months to surface)
Reversibility Score = RC + PBR + DL + OLT
A score of 4 to 8 represents a highly reversible, low-risk decision that warrants minimal upfront validation — ship it, observe it, and iterate. A score of 14 to 20 represents a high-commitment, difficult-to-reverse decision that warrants shadow architecture validation, extended canary exposure, and formal architecture review.
Why This Scoring Changes Software Development Speed
The most common cause of unnecessary slowdown in architecture decision-making is treating a score-6 decision with score-18 levels of caution. Teams spend two weeks in design review for a caching layer change that could be safely shipped and observed in two days.
Reversibility scoring creates permission backed by explicit reasoning rather than gut feel to move faster on low-commitment decisions while maintaining rigour where it genuinely matters. In practice, teams that adopt this framework find that the majority of their architectural decisions score below 10, meaning most of their caution has been misapplied.
This is one of the core mechanisms behind the 3x software development speed improvement that shadow architecture enables. It is not just about parallel validation, but it is about eliminating the paralysis that gets attached to decisions that do not actually warrant it.
Continuous Integration Strategies That Support Shadow Architecture
Shadow architecture does not exist in isolation. It works best when embedded within a mature continuous integration strategy. Specifically, several CI practices make shadow architecture easier to implement and sustain:
Trunk-based development Short-lived branches and frequent integration to the trunk reduce the divergence between what is running in shadow and what will eventually reach production. Long-lived feature branches are the enemy of meaningful shadow validation because by the time the branch is ready to shadow, the production baseline has moved significantly.
Contract testing Before a new service or component enters shadow mode, contract tests validate that its interface is compatible with the systems it will interact with. This prevents a class of divergence failures in shadow that are caused by interface mismatches rather than logic errors, keeping the signal clean.
Automated divergence analysis Raw divergence logs between shadow and production are too noisy to review manually at scale. Effective continuous integration strategies for shadow architecture include automated analysis layers, typically using statistical sampling and anomaly detection that surface meaningful divergences and filter out expected differences (such as timestamps or session tokens).
Observability-first instrumentation Shadow environments need the same level of instrumentation as production: distributed tracing, structured logging, and metric emission. Teams that treat shadow as a “throwaway” environment and skip proper observability setup lose most of the diagnostic value the pattern offers.
Risk Management in Software Architecture: What Shadow Architecture Gets Right
Traditional risk management in software architecture tends to focus on prevention — more testing, longer review cycles, more sign-offs. This approach has a ceiling. You cannot test your way to zero risk, and at some point the cost of additional prevention exceeds the cost of the incidents you are trying to prevent.
Shadow architecture reframes risk management around containment and observability rather than prevention. The question shifts from “how do we stop bad things from happening?” to “how do we ensure that when something unexpected happens, we know about it instantly and it does not affect users?”
This is a more productive frame for several reasons:
- It acknowledges that complex systems will behave unexpectedly under real load, regardless of how thoroughly they were tested.
- It aligns risk management investment with actual impact — you are not slowing down everything to prevent edge cases; you are ensuring edge cases surface safely.
- It creates a learning loop. Shadow environments generate diagnostic data about failure modes that pure prevention strategies never surface, because the failures only occur under real production conditions.
The practical result is that risk management in software architecture becomes a continuous, low-overhead activity rather than a periodic, high-stakes gate – which is precisely the condition that allows software development speed to increase sustainably.
Implementing Shadow Architecture: A Practical Starting Point

If your team has not implemented shadow architecture before, the entry point does not need to be sophisticated. Here is a pragmatic sequence:
Phase 1 — Pick one high-risk upcoming change Identify a change in your current roadmap that scores above 12 on the reversibility scoring model. This is your shadow architecture pilot. Do not try to retrofit the entire release pipeline in one go.
Phase 2 — Implement traffic mirroring at the proxy layer Use your existing load balancer or API gateway to duplicate a percentage of production traffic (start with 5 to 10%) to the shadow environment. Envoy’s mirroring filter, NGINX’s mirror directive, and AWS Application Load Balancer’s traffic mirroring are all well-documented starting points.
Phase 3 — Build a basic divergence log Log shadow responses alongside production responses with a shared request identifier. Even a simple comparison that flags HTTP status code divergences and response time outliers will surface the majority of meaningful differences.
Phase 4 — Define your promotion criteria Before the shadow runs, define explicitly what “good enough to promote” looks like: error rate below X%, response time within Y% of production, zero divergences on critical response fields. This prevents the shadow from running indefinitely without a clear decision trigger.
Phase 5 — Run your first parallel canary universe Once the basic shadow infrastructure is working, extend it to a second variant. You now have two candidate implementations running in parallel against real traffic, with clear scoring criteria for which one earns the right to be promoted.
The Production Stability Payoff
The ultimate measure of shadow architecture is not how fast teams ship — it is how stable production remains as shipping frequency increases. These two outcomes are in tension in traditional release pipelines and in alignment in shadow architectures.
The data supports this. According to the DORA 2023 report, elite DevOps performers have a change failure rate of 0 to 15% compared to 46 to 63% for low performers. (Source: Google Cloud DORA Report 2023) High-frequency shipping and low failure rates are not a trade-off in mature engineering organisations — they are correlated. The mechanism is exactly what shadow architecture provides: real-traffic validation that surfaces failures before users encounter them.
Production stability techniques like shadow architecture also pay dividends in team confidence and culture. When engineers trust that the validation pipeline will catch problems before they reach users, the psychological cost of shipping drops significantly. This is not a soft benefit but is a direct driver of deployment frequency, which is one of the strongest predictors of overall organisational performance in software delivery.
Conclusion
The “shadow architecture” method is not a silver bullet, and it does require investment to implement properly. But the core insight it rests on is sound: the bottleneck to faster, safer software delivery is not engineering effort or testing thoroughness, but it is the structural design of how changes are validated before they reach users.
Parallel canary universes give teams real-traffic signals without real-user risk. Architecture decision reversibility scoring gives teams explicit permission to move fast on low-commitment choices and rigorous validation on high-commitment ones. Together, they create the conditions under which shipping 3x faster and maintaining production stability are not competing priorities; they are the same outcome.
The teams that ship fastest are not the ones taking the most risk. They are the ones who have built the infrastructure to make risk visible, containable, and manageable at speed. Shadow architecture is how you build that infrastructure.If this is something your team is working through and you want to think it through with someone who has navigated this from both the engineering and product sides, reach out at [email protected].


